Sesión de la primera temporada
Sesión 6 - Ingesta de datos en Microsoft Fabric (3ra parte)
Resumen
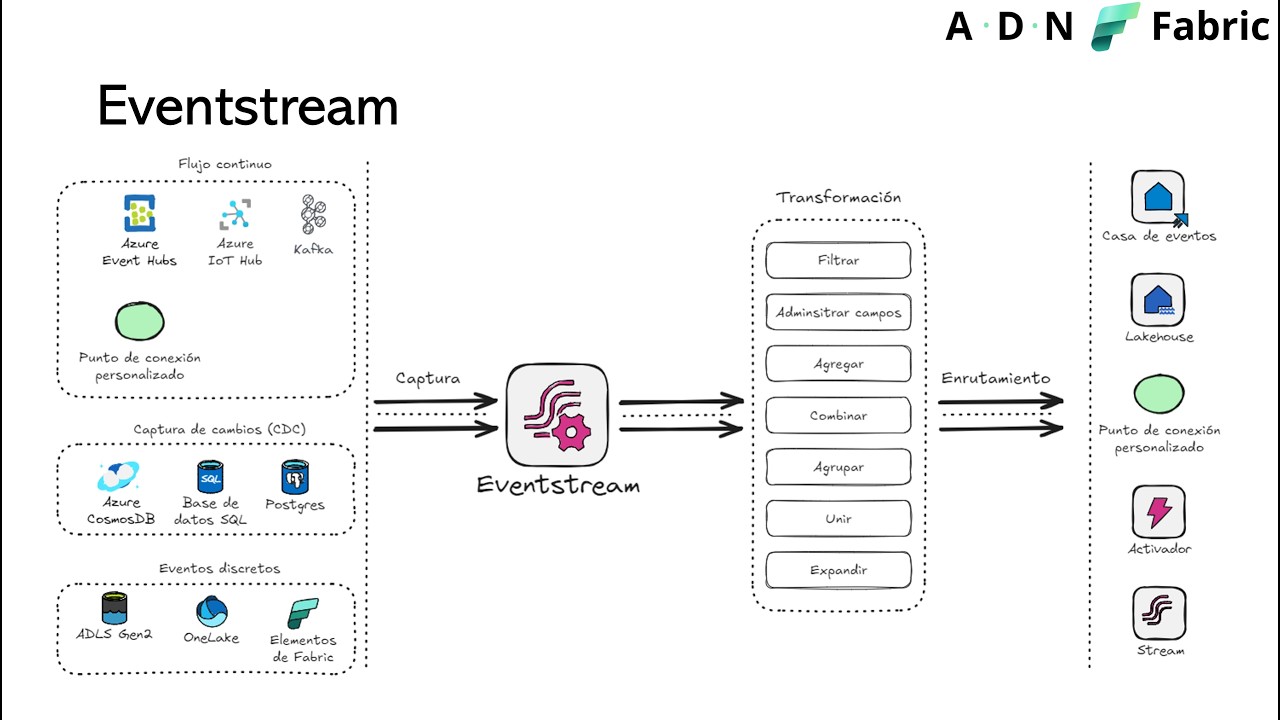
La sesión se centró en cerrar la serie dedicada a la ingesta de datos en Microsoft Fabric, poniendo el foco en Eventstream como componente especializado en el procesamiento de eventos en tiempo real. Se explicó que Eventstream actúa como sucesor de los flujos de datos en streaming de Power BI y que guarda similitudes con Azure Stream Analytics. Su funcionamiento se resumió en tres capacidades principales: captura de eventos desde múltiples orígenes, transformación de esos eventos y enrutamiento hacia distintos destinos. Aunque la sesión se enfocó en la ingesta, también se dejó claro que Eventstream es una pieza clave para escenarios de analítica en tiempo casi real dentro de Fabric.
En cuanto a los orígenes de datos, se distinguieron tres grandes grupos. Primero, los flujos continuos de datos, típicos de dispositivos o sensores conectados mediante servicios como Azure Event Hubs, Azure IoT Hub o Kafka, e incluso mediante un punto de conexión personalizado directo a Eventstream. Segundo, la captura de cambios (CDC) desde bases de datos transaccionales, para detectar inserciones, modificaciones o borrados en tecnologías como Azure SQL, PostgreSQL o Cosmos DB. Tercero, los eventos discretos, generados por cambios en archivos y carpetas dentro de OneLake, Azure Data Lake o incluso por ejecuciones de elementos de Fabric, como canalizaciones de datos. Esta clasificación es especialmente relevante para profesionales de datos porque ayuda a elegir la estrategia de ingesta según la naturaleza y frecuencia del evento.
La parte práctica mostró varios ejemplos de uso de Eventstream con distintos destinos de almacenamiento de Fabric. Se trabajó con una Eventhouse y su base de datos KQL como destino para datos en tiempo real, y también con un Lakehouse para almacenar información con una granularidad distinta. En un ejemplo, se usó un origen de datos de muestra sobre alquiler de bicicletas en Londres y se añadió una transformación para incorporar la fecha y hora del evento antes de almacenarlo en KQL. En otro, se aplicó una agregación cada cinco minutos para guardar los datos en un Lakehouse orientado a análisis posterior. También se mostró que un mismo Eventstream puede enviar datos a múltiples destinos simultáneamente, lo que permite consolidar arquitecturas de ingesta y servir distintos casos de uso con un solo flujo.
Además, se presentó un ejemplo de eventos discretos desde OneLake, donde se capturaban acciones como creación de archivos, creación de carpetas o modificaciones dentro de un Lakehouse. Esto permitió ilustrar que Eventstream no solo sirve para telemetría o streaming clásico, sino también para monitorizar cambios estructurales en entornos de datos de Fabric. Para los profesionales de datos, este punto es importante porque amplía el alcance de la ingesta hacia escenarios de automatización, auditoría y activación de procesos basados en eventos.
Finalmente, Ana y Diana resumieron los distintos métodos de ingesta vistos a lo largo de las tres sesiones: Dataflows Gen2, Data Pipelines, Copy Jobs, notebooks Spark, shortcuts, mirroring y Eventstream. La recomendación principal fue elegir la tecnología según varios criterios: volumen de datos, frecuencia de actualización, necesidad de tiempo real, tipo de carga completa o incremental y nivel de habilidades técnicas del equipo. También destacaron que, cuando se necesita un conector específico o complejo, Dataflows Gen2 sigue siendo una opción muy valiosa por su amplio catálogo de conectores integrados. En conjunto, la sesión dejó una visión práctica para seleccionar el mecanismo de ingesta más adecuado en Fabric según el escenario técnico y operativo.
Video