Sesión de la primera temporada
Sesión 5 - Ingesta de datos en Microsoft Fabric (2da parte)
Resumen
La sesión se centró en la ingesta de datos en Microsoft Fabric, profundizando en dos mecanismos clave: los accesos directos (shortcuts) y los reflejos (mirroring). Los ponentes explicaron cómo Fabric permite unificar el acceso a datos distribuidos entre distintos dominios, nubes y cuentas sin necesidad de duplicarlos siempre físicamente. La idea principal fue mostrar que la ingesta en Fabric no se limita a copiar datos, sino que también puede consistir en virtualizar el acceso o replicar inteligentemente la información según el tipo de origen.
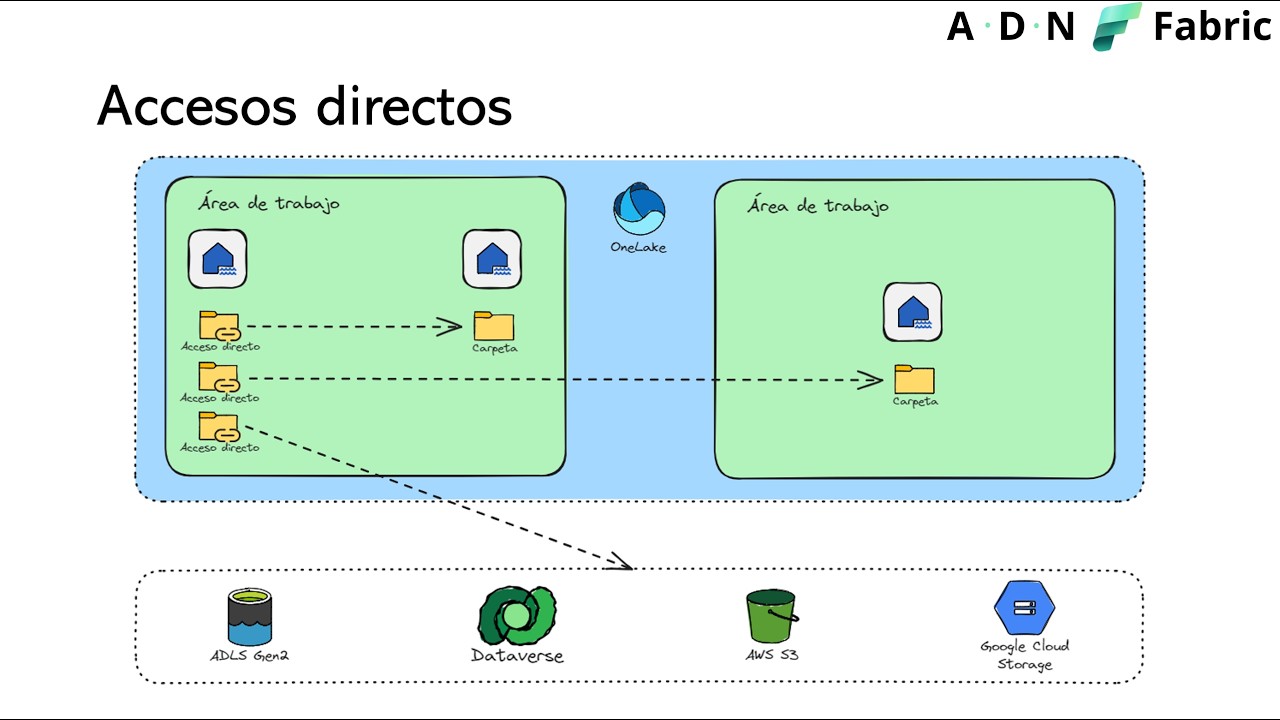
En la parte de accesos directos, se explicó que son objetos de OneLake que apuntan a datos ubicados dentro o fuera de Fabric, funcionando de forma similar a vínculos simbólicos. Estos accesos pueden crearse en Lakehouse y en bases de datos KQL, permitiendo consumir datos desde orígenes como Azure Data Lake Storage, Amazon Web Services o OneLake. Se destacó que en Lakehouse los accesos a tablas requieren formatos como Delta o Iceberg, y que en este último caso Fabric realiza una virtualización de metadatos para mapear el esquema hacia Delta. En KQL, los shortcuts se tratan como tablas externas, consultables mediante external table, y pueden aprovechar una opción de aceleración cuando el origen está en formato Delta.
También se remarcó el valor práctico de los accesos directos para los profesionales de datos: eliminan copias innecesarias, reducen la latencia asociada a movimientos intermedios y simplifican la administración porque OneLake centraliza permisos y credenciales. Esto facilita que distintas cargas de trabajo de Fabric accedan a los mismos datos sin tener que configurar conexiones independientes para cada servicio. En términos arquitectónicos, esto favorece escenarios de gobierno, reutilización y acceso unificado a datos distribuidos.
La segunda gran parte de la sesión abordó los reflejos (mirroring) como alternativa cuando no es posible usar accesos directos, especialmente con bases de datos externas cuyos formatos no son compatibles directamente con Delta. En estos casos, Fabric replica los datos en OneLake, convirtiéndolos desde su formato propietario a formato Delta, lo que permite tratarlos como datos nativos de Fabric. Se explicó que esto habilita capacidades como el uso de Direct Lake en modelos semánticos, transformaciones con cuadernos Spark, consultas SQL y combinación con datos de Lakehouse o Warehouse. A diferencia de los shortcuts, los reflejos sí ocupan almacenamiento físico en el área de trabajo y pueden implicar costes adicionales.
Finalmente, se presentaron los tipos de reflejo disponibles, destacando el reflejo de base de datos y el reflejo de metadatos. El primero genera una copia Delta de los datos junto con un punto de conexión SQL y un modelo semántico por defecto. El segundo, orientado inicialmente a Databricks, replica solo la metadata —esquemas, tablas y estructura— mientras que los datos permanecen en el origen y se consumen mediante accesos directos. Para los profesionales de datos, el mensaje más relevante es que Microsoft Fabric ofrece varias estrategias de ingesta según el equilibrio deseado entre virtualización, rendimiento, coste, almacenamiento y facilidad operativa, lo que amplía notablemente las opciones de diseño de arquitecturas modernas de datos.
Video
Diapositivas
📥 Descargar diapositivas (PDF)