Sesión de la primera temporada
Sesión 4 - Ingesta de datos en Microsoft Fabric (1ra parte)
Resumen
La sesión se centra en la ingesta de datos en Microsoft Fabric desde una perspectiva introductoria, explicando primero los principios generales que todo profesional de datos debe considerar antes de cargar información. Se insiste en la importancia de identificar correctamente los orígenes de datos —bases de datos, archivos CSV, Excel u otras fuentes— porque de ello dependen los procesos de extracción, el impacto sobre los sistemas origen y la posible necesidad de una zona intermedia de staging previa a la capa Bronze. También se aclara que esta zona de staging no equivale a la capa Bronze, sino que puede ser un paso anterior necesario por motivos de seguridad, cifrado, herramientas disponibles o complejidad de los conjuntos de datos.
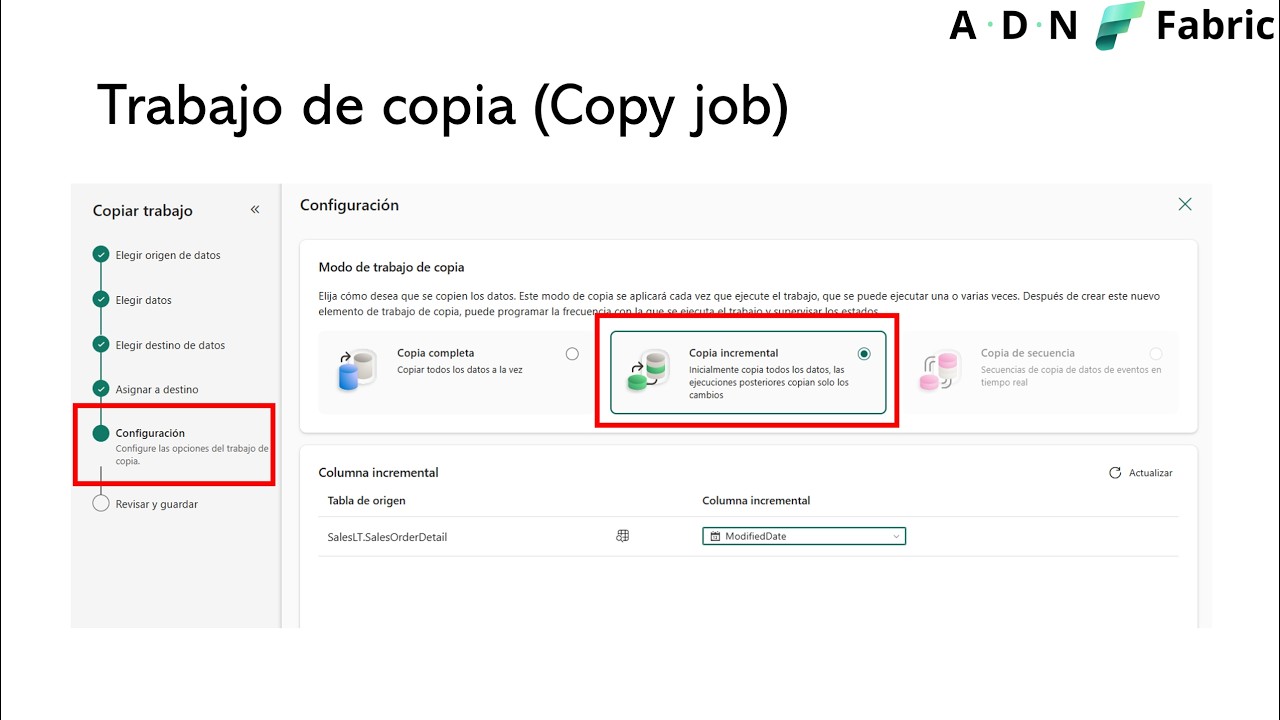
Otro bloque importante de la sesión aborda las estrategias de carga, distinguiendo entre carga inicial y carga incremental. La carga inicial se describe como el proceso completo y costoso de traer todo el histórico al nuevo almacenamiento, mientras que la incremental permite actualizar solo los cambios periódicos, lo que exige mecanismos de seguimiento de modificaciones en origen. En este contexto se repasan conceptos clásicos del modelado dimensional que siguen plenamente vigentes en Fabric, como el uso de claves subrogadas para identificar registros de forma técnica y mantener la trazabilidad de cambios, frente a las claves empresariales o naturales, que sí tienen significado para el negocio.
La sesión también explica cómo tratar los datos según su estructura y frecuencia de llegada. Se comparan los enfoques de schema-on-read y schema-on-write: el primero, más flexible, resulta adecuado para datos semiestructurados o no estructurados; el segundo, más estricto, se utiliza cuando el esquema está definido de antemano, como ocurre en bases de datos estructuradas. Además, se diferencia entre carga por lotes y procesamiento en tiempo real o streaming, destacando que Fabric dispone de una arquitectura especialmente preparada para escenarios en tiempo real, algo relevante para casos como detección de fraude o análisis inmediato de eventos.
Desde el punto de vista del diseño de almacenes analíticos, se recuperan fundamentos del modelado dimensional de Kimball, especialmente el tratamiento de dimensiones lentamente cambiantes (SCD) y la necesidad de controlar cómo evolucionan ciertos atributos a lo largo del tiempo. También se menciona la captura de datos modificados (CDC, Change Data Capture), ya sea mediante SQL, procesos automatizados o triggers, como mecanismo clave para detectar inserciones, actualizaciones y eliminaciones. En la carga de tablas de hechos se recuerda la importancia de cargarlas después de las dimensiones para evitar registros huérfanos y asegurar la correcta relación mediante claves subrogadas.
Finalmente, la sesión aterriza estos conceptos en las tecnologías concretas de Microsoft Fabric, explicando que la elección del método de ingesta depende del volumen de datos, el tipo de datos, la frecuencia de actualización y las capacidades del equipo. Para cargas por lotes y alto rendimiento se destacan las canalizaciones (pipelines) y Copy, mientras que para escenarios low-code se recomiendan Dataflows, heredando la experiencia de Power Query. Para datos semiestructurados o necesidades más técnicas se mencionan Notebooks, y para integración entre distintos almacenes se introducen los shortcuts. En escenarios de tiempo real, Fabric ofrece componentes como Real-Time Intelligence, Event Streams y Eventhouse, lo que convierte a la plataforma en una opción flexible tanto para perfiles sin código como para equipos con capacidades avanzadas de ingeniería de datos.
Video