Sesión de la primera temporada
Sesión 3 - Almacenar datos en Microsoft Fabric
Resumen
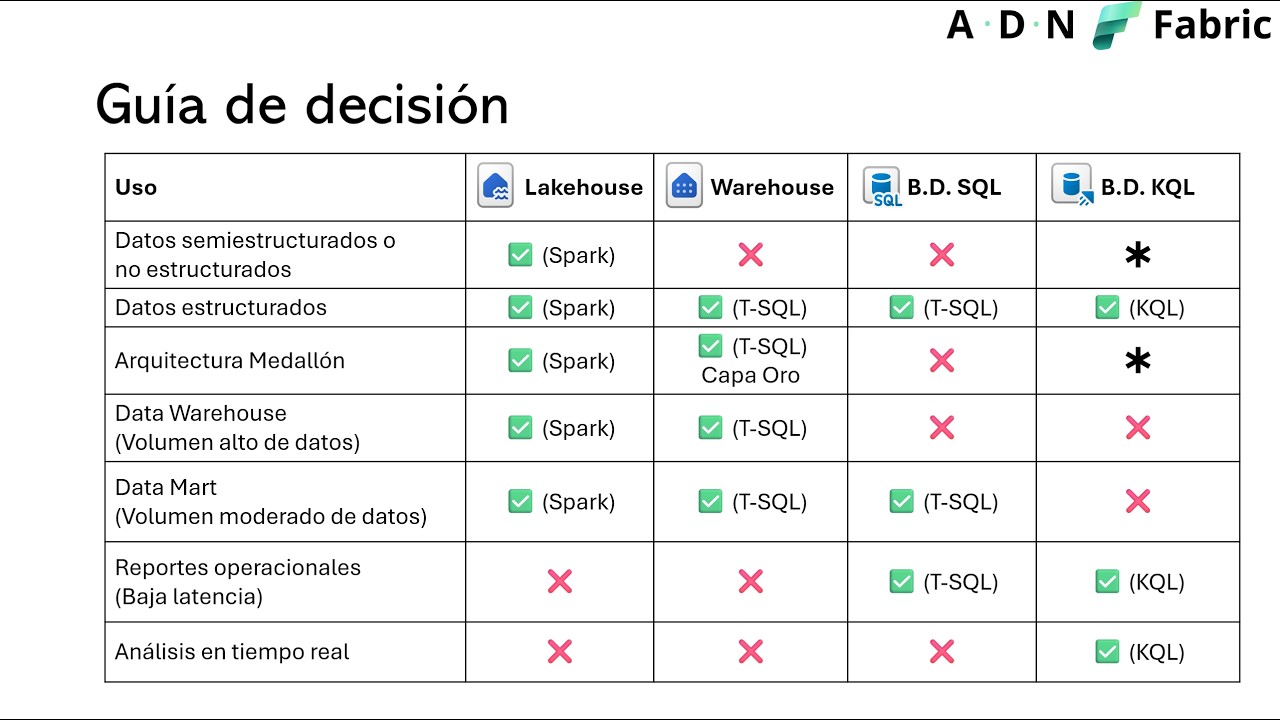
La sesión se centra en las opciones de almacenamiento de datos dentro de Microsoft Fabric, con un enfoque introductorio para quienes están empezando a trabajar con la plataforma. Los ponentes explican cómo crear y utilizar estos componentes dentro de áreas de trabajo con capacidad Premium o en modo de prueba, destacando que Fabric permite practicar con datos de ejemplo proporcionados por Microsoft. A lo largo de la sesión se presentan principalmente tres formas de almacenamiento: el Lakehouse, el Data Warehouse y una introducción a las bases de datos SQL incorporadas recientemente en Fabric.
Uno de los temas principales es el Lakehouse, descrito como una combinación entre las capacidades analíticas SQL de un almacén de datos relacional y la flexibilidad y escalabilidad de un lago de datos. Se explica que al crear un Lakehouse se generan también un modelo semántico predeterminado y un punto de conexión SQL Analytics de solo lectura. Además, se muestra cómo cargar datos mediante distintas opciones, incluidos los datos de muestra, y cómo explorar tablas, archivos e imágenes dentro del entorno. También se introduce el uso de tablas Delta, fundamentales en Fabric, apoyadas en Delta Lake sobre Apache Spark, con archivos Parquet y registros Delta Log, lo que aporta capacidades avanzadas para análisis y gestión de datos.
Otro concepto importante es OneLake, presentado como el almacenamiento unificado de Microsoft Fabric. La sesión explica su integración con el explorador de archivos de Windows mediante una aplicación de sincronización, lo que permite ver áreas de trabajo, tablas y archivos como si fueran carpetas locales. Se aclara que esta sincronización no descarga directamente todos los datos, sino que crea marcadores de posición y mantiene actualizados metadatos, carpetas y cambios realizados. Para los profesionales de datos, esto resulta especialmente relevante porque facilita el acceso, la organización y la interacción con los datos almacenados en Fabric desde herramientas y flujos de trabajo más familiares.
En cuanto al Data Warehouse de Fabric, se presenta como un almacén analítico relacional basado en esquema, orientado al uso de Transact-SQL. A diferencia del punto de conexión SQL del Lakehouse, aquí el acceso no es solo de lectura, sino también de escritura, permitiendo consultar datos y crear objetos de base de datos como tablas, vistas, esquemas, funciones y procedimientos almacenados. La interfaz recuerda a SQL Server Management Studio, lo que facilita la adopción por parte de perfiles con experiencia en entornos SQL tradicionales. También se destaca la posibilidad de cargar datos mediante flujos de datos, canalizaciones o código SQL, así como la creación de modelos semánticos e informes directamente desde el almacén.
Para los profesionales de datos, la sesión deja varios mensajes clave: Microsoft Fabric unifica distintos paradigmas de almacenamiento y análisis en una misma plataforma; permite empezar rápidamente con entornos de prueba y datos de ejemplo; y ofrece una transición natural tanto para perfiles orientados a ingeniería de datos y Spark como para especialistas en SQL y BI. La combinación de Lakehouse, OneLake, modelos semánticos, SQL Analytics Endpoint y Data Warehouse muestra cómo Fabric busca centralizar almacenamiento, consulta, modelado y consumo analítico en un ecosistema integrado y accesible.
Video